MCP vs CLI vs API: Battle of the three-letter acronyms
Why does MCP exist if LLMs can already use APIs and CLIs without any issues?
2026-02-04
·By Kashish Hora, Co-founder of MCPcat
One of the most common questions we seem to get from the general community is why an MCP server is necessary when an API or CLI can do the job. It's a pretty common question.
 No seriously, it's a VERY common question.
No seriously, it's a VERY common question.
It's also not a bad question. Creating a new standard that people invest time and effort into improving and companies invest time and effort into building on top of is a lot of waste if there's already an existing standard or norm that works well.
 XKCD said it best.
XKCD said it best.
Here at MCPcat we're invested in MCP, and that's because we believe it will one day be as important and fundamental as HTTP is today. AI agents are getting better and there will need to be a standard way for agents to access other products and data, which we believe is MCP. And if you're building an MCP server, knowing what AI agents are doing with your server is paramount. That's why we're building MCPcat. But I digress.
In this post we wanted to answer one simple question: Why the heck does MCP exist if APIs and CLIs already get the job done?
First, an aside
We’ve been building MCPcat since shortly after the protocol was released. Since then, the most common criticism of MCP was that it seems unnecessary and overengineered. Just as the protocol has gained momentum, so has the criticism.
The goal with writing this post is to present a double-contrarian viewpoint in favor of MCP. It may not be necessary, as many people, ourselves included, are big believers in MCP and fee l that it’ll become so standardized that we’ll start taking it for granted.
But for those that don’t share a similar viewpoint, this blog may shed some light on why it’s necessary to have MCP but also why, today, it feels unnecessary and overengineered.
Let’s talk about the ideal user
I have a product background, and so I tend to start most discussions by thinking about “Who is the ideal user?”
CLIs were made for human developers. Some CLIs have terrible documentation but developers still find them very useful through lots of time and muscle memory invested learning all the commands and different arguments. A great example of this is git or vim. Hard to get started with, but once you, the human, learn how to use them, you’re 10x more productive.
APIs were made for deterministic code. Developers are still the authors, but the intended users are other systems or applications that are preprogrammed and made to do something specific every single time. The user of an API isn’t “deciding” what to do at any point in time, it’s just following whatever it was programmed to do. And as a result, APIs generally have fantastic documentation (since humans need to understand them), but are insanely granular and specific since systems that call APIs need to be very specific and can’t deal with any ambiguity.
And now let’s bring LLMs into the mix. Language models aren’t humans. They don’t have persistent long-term memory, the ability to reason, or the ability to update their priors and form new logical connections.
But they’re also not code. LLMs can “reason” at very basic levels and they’re not deterministic. At times, it feels like an LLM is deciding what to do in the moment, even though in reality it’s not.
So what do you do? Do you just give an LLM a CLI and hope that it figures it out, just as a human would? Well, sure. In some cases that works totally fine. I use the Github CLI with Claude Code and it works perfectly.
Or instead, do you just give it API documentation and tell it to figure out how to interact with another product? Sure, I do that too. I used to copy-paste Stripe’s API docs right into ChatGPT and have it generate various custom dashboards for us.
But none of these solutions are perfect. That is to say, CLIs with poor documentation will still be perfect for their users who already know how to use them. And APIs with frustratingly granular designs will still be perfect for machines that are calling them. But neither of those are perfect for an LLM.
Enter MCP
So a new standard had to be created.
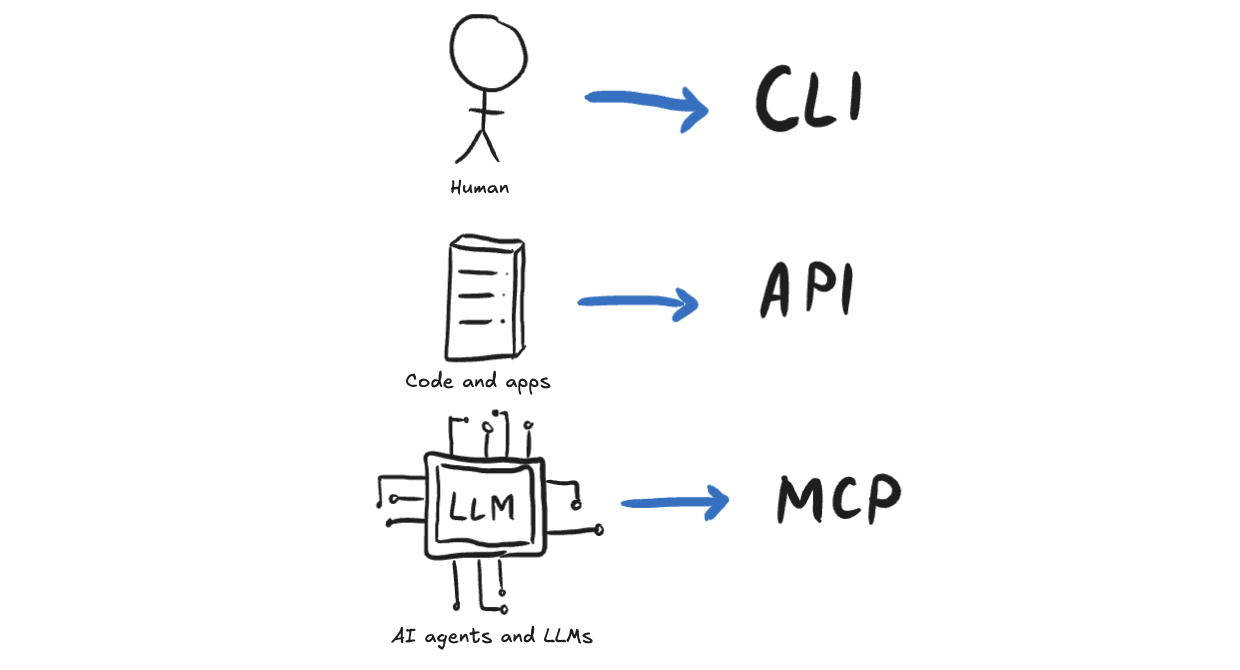
It’s not quite a CLI. While MCP servers are lightweight enough to be run locally, they can also be hosted on the cloud and run remotely, allowing users to interact with them similar to any other server while giving developers the ability to easily maintain and update them as they would any other web product. And CLIs don’t enforce strict documentation requirements, although developers include them anyway to help users. But an MCP server is 80% documentation, what with all the tool names, descriptions, and annotations.
But it’s also not an API. The tools in an MCP server are designed to be higher-level than just API endpoints. A tool is designed to accomplish a user action in the same logical way a user would think about doing things.
The magic of MCP is that it’s built specifically for LLMs and AI agents, which are an entirely new type of user that didn't exist until a few years ago. And these agents have the ability to reason a little and make intelligent (seeming) decisions, but they lack the memory and expertise of humans.
But what about [insert shortcoming of MCP here]?
The short answer is we don’t have answers to everything yet. MCP was created in 2024, which by protocol standards is an absolute baby. The fact that it’s seen such explosive growth and adoption is just a testament to how many people are excited about it, see its potential, and some hype.
There are still glaring holes in the protocol that need to be fixed. Some of those fixes will come from changes and improvements to the protocol, but other things will be solved by third-party products. The reason we started building MCPcat was because we saw a hole in the analytics and observability stack of MCP. The users of MCP servers aren’t humans, they’re AI agents, and understanding what they’re doing and where they run into issues requires new tooling than what was out there.
But there are lots of other things the protocol needs improvement on. Security and authentication come to mind.
Some of the worlds most talented developers are working to improve MCP the protocol to fix holes and handle more complex workflows in a simple and intuitive way.
So it’s fair to critique the protocol’s state today, but just be aware that it’s open-source and its shortcomings are common knowledge and are being actively addressed.